TOC
本文讨论Netty数据接收的过程,分为两部分进行:1. 数据接收的缓存结构; 2. 数据写入缓存的过程。
先讨论第一部分,数据的缓存结构。缓存是在处理速率不同的多种设备间共享数据常用的手段,NIO中就提供了用于缓存数据的ByteBuffer。而Netty的设计者认为nioByteBuffer的实现不够好,所以重新实现了一个ByteBuf用于缓存数据。那么,这两者有什么差异?使用上有什么不同?
nio ByteBuffer VS. netty ByteBuf
ByteBuffer
ByteBuffer是从JDK1.4开始提供的基于字节的缓存。按照java doc的说法,ByteBuffer提供以下6种类型的操作:
- 绝对位置或相对位置的
get/put操作用于读写单个byte - 批量读
bulk get,用于将ByteBuffer中的字节批量读入byte数组 - 批量写
bulk put,用于将byte数组或其余ByteBuffer批量写入ByteBuffer - 在绝对位置或相对位置上,直接将
byte(s)解析为基础类型 - 创建ByteBuffer视图
- 压缩/复制/切割ByteBuffer
下图是ByteBuffer的结构示例。
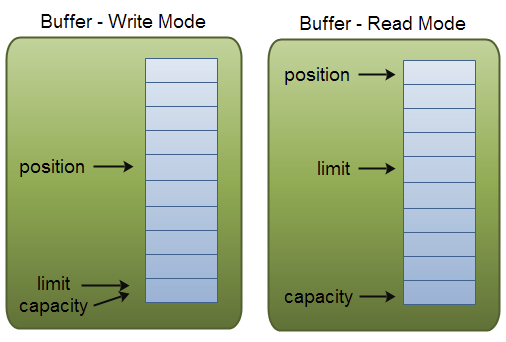
在ByteBuffer类中有一个字节数组hb,这是实际保存字节内容的容器。并定义了保存读写位置的三个属性:position、limit、capacity,在读写模式下这些属性分别表示:
读模式
capacity:Buffer最大容量
limit: 最大可读位置
position:当前读位置(0起始, 最大为limit-1)
写模式
capacity:Buffer最大容量
limit:跟capacity相等
position:当前写位置(0起始, 最大为capacity-1)
你大概已经猜到上述的六种方法如何在ByteBuffer的双指针数组结构中实现,但当你在nioByteBuffer源码中寻找对应的方法时,几乎所有的方法都标记为abstract留给子类实现。ByteBuffer提供了两种实现:堆内的HeapByteBuffer和直接操作堆外内存的DIrectByteBuffer。他们继承关系如下:
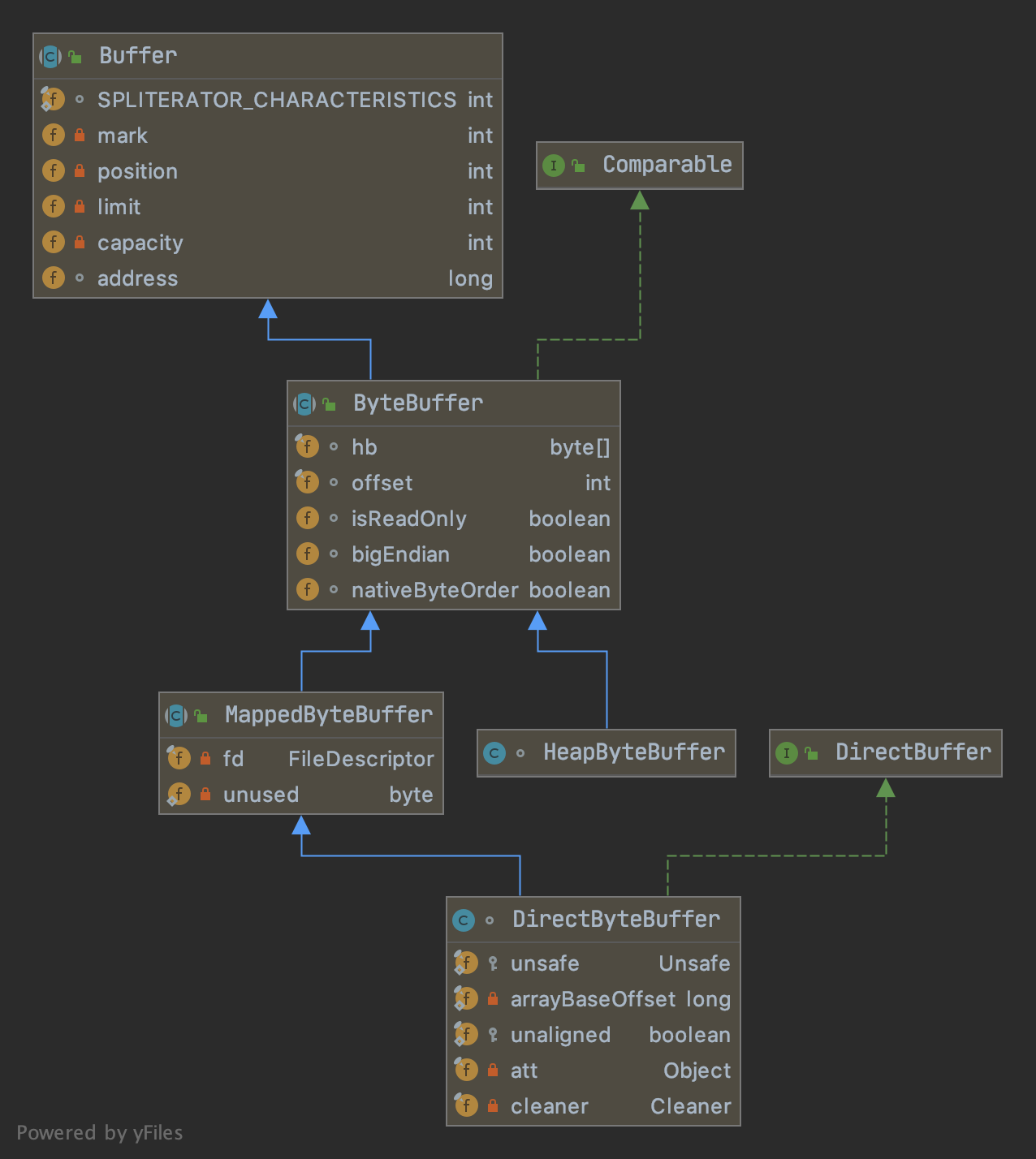
ByteBuffer提供了两个静态方法用于创建两种类型的Buffer:
# ByteBuffer.java
// 创建堆外内存Buffer
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}
// 创建堆内内存Buffer
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
return new HeapByteBuffer(capacity, capacity);
}
堆内内存Buffer比较简单,给定一个capacity,实例化的时候创建一个大小为capacity的byte数组并初始化相关属性即可。
堆外内存DirectByteBuffer的实现则相对复杂,需要依赖JDK直接参与内存的申请,操作和回收等工作。限于篇幅,这里不做展开。
ByteBuf
这样看起来java nio已经提供了比较完善的功能,那为什么Netty还有单独开发一个ByteBuf?下标比较了两个缓存的优缺点:
| ByteBuffer | ByteBuf | |
|---|---|---|
| 扩容 | 长度固定,需手动扩容 | 自动扩容 |
| 位置指针 | 单指针,需通过flip()来切换读写模式 |
双指针,无读写模式区分 |
| 读写功能 | – 不支持无符号类型或字符串 – 不支持查找 | – 支持类型更丰富的基础类型读写,如unsigined int, string – 支持查找操作 |
| 标记&重置 | 仅支持一个marker | 针对读指针和写指针分别有一个marker |
| 扩展性 | ByteBuffer的实现落在子类(package标记),所以无法扩展 |
可以自由扩展 |
| 性能 | 一般 | 更高 |
列表中的头几个优势可以简单地理解其原理,本质是由于ByteBuf是一种更优秀的封装。但是性能,就有必要详细地解释下,同样是Buffer为什么ByteBuf可以做到更优秀。
ByteBuf高性能的原因
减少初始化
分配新的java.nio.ByteBuffer时,其内容将需要以0填充。 这种“填充”会消耗CPU周期和内存带宽。 通常,在Buffer分配之后会立马填充业务数据,因此这样的“填充”并不会带来任何好处。
对象重用
java.nio.ByteBuffer依赖于JVM进行垃圾收集器。 这种回收手段对堆内存有效,但对堆外内存的回收却不够理想。 在设计上,堆外内存对象预计将存活很长的时间。 因此,通过ByteBuffer分配许多短寿的堆外内存通常会导致OutOfMemoryError。 同样,(通过虚引用实现)释放堆外内存也不是很快(这也不是JDK推荐的做法)。
而ByteBuf的生命周期绑定到其引用计数上。 当其计数变为零时,他的指向的内存区域(underlying memory region,byte []或堆外内存空间)被显式取消引用,内存空间被释放或返到池中(而不是直接释放)。
对象池化
Netty还提供了可靠的缓冲池实现,不会将其缓冲区清零而浪费CPU周期或内存带宽:
ByteBufAllocator alloc = PooledByteBufAllocator.DEFAULT;
ByteBuf buf = alloc.directBuffer(1024); // 分配内存
...
buf.release(); // 内存还给对象池
在回收对象池的时候,ByteBuf选择了引用计数的方法(JVM则是可达性分析法)。关于ByteBuf如何管理对象池,在这篇文章进行了更深入的讨论。
因此根据 池化、堆内堆外这两个维度的区分,ByteBuf共有4种类型:
PooledDirectByteBufPooledHeapByteBufUnPooledDirectByteBufUnPooledHeapByteBuf
到这里写入数据的临时目标缓存Buffer已经简单介绍完毕,下面将要进入正式的读取流程。
读写数据
在本系列的前一章已经给你介绍了连接建立的过程,这个时候回到WokerGroup线程池内的线程NioEventLoop,线程的run()内一直通过一个processSelectedKeys方法检查是否有新的SelectionKey时间进来:
private void processSelectedKeys() {
if (selectedKeys != null) {
// flip 切换写入数组,并返回旧的数组
processSelectedKeysOptimized(selectedKeys.flip());
} else {
processSelectedKeysPlain(selector.selectedKeys());
}
}
这里提供了两个处理SelectedKeys的方法,是由于Netty对基于HashSet的Selector做了优化,单独写了一个SelectedSelectionKeySet替代HashSet。这本质上不是一个Set而是数组。底层通过两个数组的交替顺序写入来保存新增的Key,避免了HashSet读写的低效。
遍历
HashSet.Iterator()与 遍历数据 的性能比较简单测试,遍历数据比Iterator的速度快2~5倍
两个processSelectedKeys方法都是遍历Selector接收的SelectedKey并最终来到:
/**
*
* @param k selectedKey
* @param ch key通过attachment保存的channel, 亦即触发此key的ch
*/
private void processSelectedKey(SelectionKey k, AbstractNioChannel ch) {
final AbstractNioChannel.NioUnsafe unsafe = ch.unsafe();
if (!k.isValid()) {
// (省略) key不可用, 异常处理...
}
try {
int readyOps = k.readyOps();
// (省略)... OP_ACCEPT事件的处理
// (省略)... OP_WRITE事件的处理
// 可读事件 or 网络连接 (断开连接也在这里进入)
if ((readyOps & (SelectionKey.OP_READ | SelectionKey.OP_ACCEPT)) != 0 || readyOps == 0) {
unsafe.read();
if (!ch.isOpen()) {
// Connection already closed - no need to handle write.
return;
}
}
} catch (CancelledKeyException ignored) {
unsafe.close(unsafe.voidPromise());
}
}
接下来代码来到unsafe#read()这是AbstractNioChannel定义的一个接口方法,这里我们调用的是哪个类实现呢?断点一下可以发现处理OP_READ的NioSocketChannel继承的是AbstractNioByteChannel,来到我们的关键代码:
# AbstractNioByteChannel.java
public final void read() {
final ChannelConfig config = config();
final ChannelPipeline pipeline = pipeline();
final ByteBufAllocator allocator = config.getAllocator();
final RecvByteBufAllocator.Handle allocHandle = recvBufAllocHandle();
allocHandle.reset(config);
ByteBuf byteBuf = null;
boolean close = false;
try {
do {
// 核心代码-1 创建ByteBuf缓存
byteBuf = allocHandle.allocate(allocator);
// 执行消费, 写入ByteBuf
allocHandle.lastBytesRead(doReadBytes(byteBuf));
// 无新消息, 释放buffer
if (allocHandle.lastBytesRead() <= 0) {
// nothing was read. release the buffer.
byteBuf.release();
byteBuf = null;
// 遵循SocketChannel的定义,若为负,表明连接已关闭
close = allocHandle.lastBytesRead() < 0;
break;
}
// 增加读入消息数量
allocHandle.incMessagesRead(1);
readPending = false;
// 触发pipeline 消费消息 事件
pipeline.fireChannelRead(byteBuf);
byteBuf = null;
} while (allocHandle.continueReading()); // 判断是否要继续读取
// 核心代码-2 读取结束后动作, 对于自适应的Allocator会根据此次读取的字节数调整
allocHandle.readComplete();
// 触发pipeline 读取消息完成 事件
pipeline.fireChannelReadComplete();
if (close) {
// 关闭pipeline
closeOnRead(pipeline);
}
} catch (Throwable t) {
// 异常处理,注意在异常处理之前也会触发Channel的readComplete事件
handleReadException(pipeline, byteBuf, t, close, allocHandle);
} finally {
// (省略) 非autoRead时复位interestOps
}
}
ByteBuf的创建是通过ByteBufAllocator接口实现的,通过他的获取方式config.getAllocator()你可以知道他是可配置的。Linux环境下默认使用的是io.netty.buffer.ByteBufUtil#DEFAULT_ALLOCATOR。他是这样定义的:
# ByteBufUtil.java
static final ByteBufAllocator DEFAULT_ALLOCATOR;
static {
/** 池化内存开关. 默认情况, 除了Android系统使用pooled */
String allocType = SystemPropertyUtil.get(
"io.netty.allocator.type", PlatformDependent.isAndroid() ? "unpooled" : "pooled");
allocType = allocType.toLowerCase(Locale.US).trim();
ByteBufAllocator alloc;
if ("unpooled".equals(allocType)) {
alloc = UnpooledByteBufAllocator.DEFAULT;
logger.debug("-Dio.netty.allocator.type: {}", allocType);
} else if ("pooled".equals(allocType)) {
alloc = PooledByteBufAllocator.DEFAULT;
logger.debug("-Dio.netty.allocator.type: {}", allocType);
} else {
alloc = PooledByteBufAllocator.DEFAULT;
logger.debug("-Dio.netty.allocator.type: pooled (unknown: {})", allocType);
}
DEFAULT_ALLOCATOR = alloc;
THREAD_LOCAL_BUFFER_SIZE = SystemPropertyUtil.getInt("io.netty.threadLocalDirectBufferSize", 64 * 1024);
logger.debug("-Dio.netty.threadLocalDirectBufferSize: {}", THREAD_LOCAL_BUFFER_SIZE);
MAX_CHAR_BUFFER_SIZE = SystemPropertyUtil.getInt("io.netty.maxThreadLocalCharBufferSize", 16 * 1024);
logger.debug("-Dio.netty.maxThreadLocalCharBufferSize: {}", MAX_CHAR_BUFFER_SIZE);
}
可见默认情况还是使用了池化的PooledByteBufAllocator.DEFAULT,后者在Linux环境下则使用堆外内存。
# PooledByteBufAllocator.java
public static final PooledByteBufAllocator DEFAULT =
new PooledByteBufAllocator(PlatformDependent.directBufferPreferred());
综合以上,Netty在Linux环境下默认使用的是堆外池化内存。
RecvByteBufAllocator
回到创建ByteBuf的代码,注意核心代码-1:
byteBuf = allocHandle.allocate(allocator);
并没有直接使用Allocator来创建ByteBuf,而是借助了一个内部定义的Handler接口。另外在创建的时候也没有指定Buffer的大小。为什么这样设计?原来:
handler是AbstractUnsafe工具类定义的一个实例变量- 基于同一个
unsafe实例对ByteBuf做的操作都会被Handler统计,包括每次分配ByteBuf的使用率 和读取消息的次数 - 基于
Handler统计结果,可以动态调整申请ByteBuf的大小 - 基于
Handler统计结果,还可以控制连续读取的次数
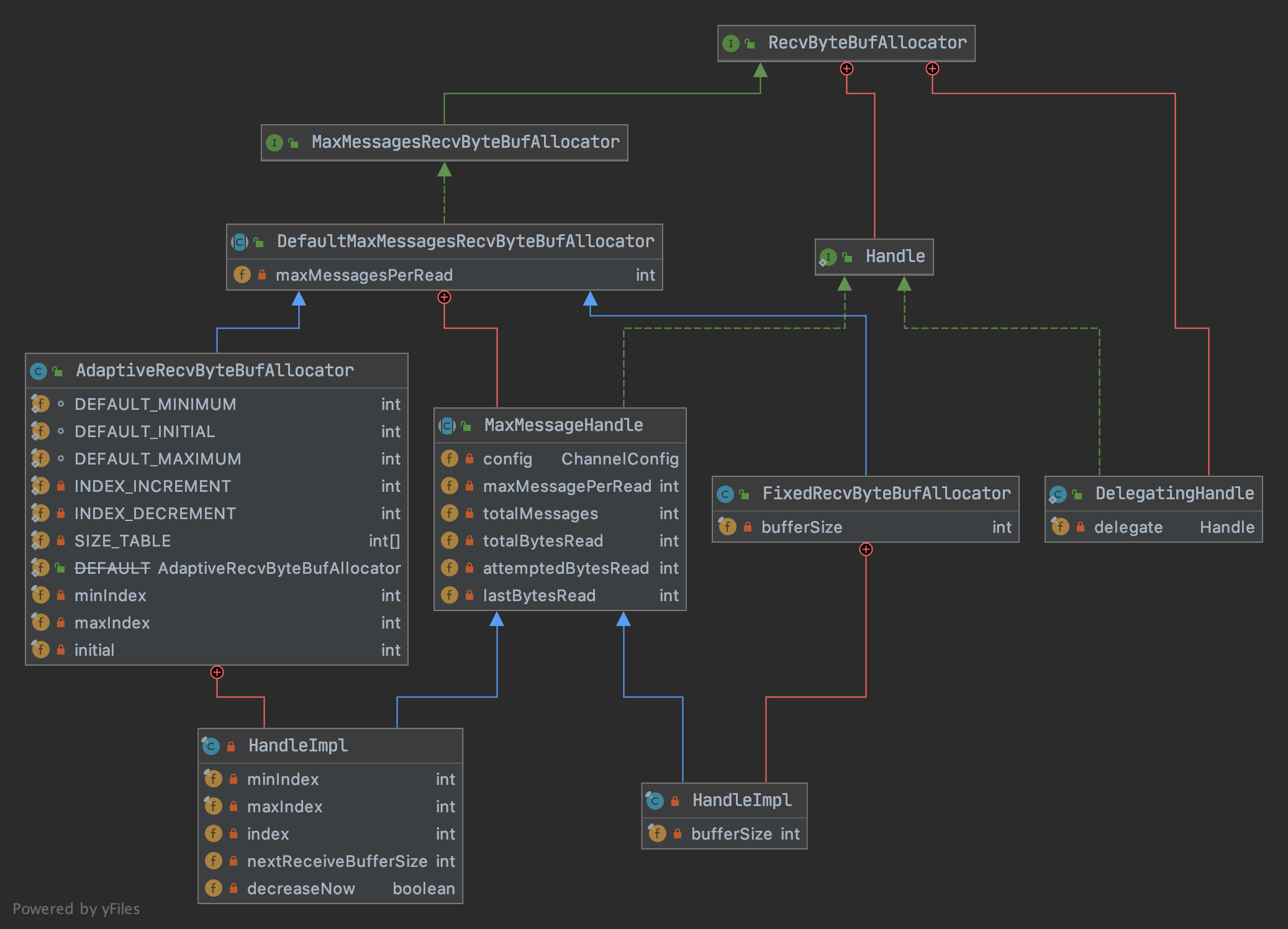
在调用allocate(ByteBufAllocator)方法创建ByteBuf是这样实现的:
# DefaultMaxMessagesRecvByteBufAllocator.MaxMessageHandle.java
@Override
public ByteBuf allocate(ByteBufAllocator alloc) {
return alloc.ioBuffer(guess());
}
alloc是负责创建指定大小的ByteBuf的,前文已经讨论过,默认情况下Linux环境创建的是堆外池化ByteBuf。而入参guess()返回的是一个整形,代表的是将要创建的ByteBuf的大小。它有两个实现:
FixedRecvByteBufAllocator.HandleImpl#guess如类名Fixed所说,这是一个固定的值,每次分配都是创建相同大小的ByteBufAdaptiveRecvByteBufAllocator.HandleImpl#guess返回值会随着Hander统计(Handler#readComplete()方法)每次ByteBuf的使用率来变化:- 若连续两次使用率低于一定的阈值,会在一个定值队列中选择一个更小的值作为下次创建ByteBuf的大小
- 若使用率只要一次大于阈值,就会增加
最后是对单个连接的连续读取次数的控制,这也是落在Handler#continueReading()方法来控制的。一方面,我们希望一次尽可能多地读取消息;同时又不希望单个连接(Channel)过多地占用读取事件,所以需要控制其最大的连续读取次数:于是有了这样的实现:
# DefaultMaxMessagesRecvByteBufAllocator.MaxMessageHandle.java
/**
* 判断一个channel是否应该继续读取数据,满足以下所有条件才继续:
* 1. config.isAutoRead() = true
* 2. attemptedBytesRead == lastBytesRead, 即本次读取消息填满了ByteBuf
* 3. totalMessages < maxMessagePerRead, 连续读取消息的次数未超过最大值, 默认为16
* 4. totalBytesRead < Integer.MAX_VALUE, 读取的消息字节数大小未超最大值
*/
public boolean continueReading() {
return config.isAutoRead() &&
attemptedBytesRead == lastBytesRead &&
totalMessages < maxMessagePerRead &&
totalBytesRead < Integer.MAX_VALUE;
}
最后你应该注意到,每完成一次读取,都会将ByteBuf作为参数触发Pipeline的fireChannelRead(ByteBuf)方法,这最终会调用Handler的channelRead()方法。这是我们下一章需要讨论的问题了,现在先来总结一下。
总结
今天我给你介绍了Netty提供的,基于nioByteBuffer开发的ByteBuf缓冲容器,以及他们的异同。它拥有诸多比ByteBuffer方便的API,但更重要的是它通过复用内存空间达到了更佳的性能。
在读取消息的时候,本质还是通过SelectionKeys#OP_READ事件的监听,但netty对Selector基于hashSet实现的selectedKey做了优化,变成双数组实现以优化性能。
最后我给你介绍了Netty是如何基于Handler+Allocator实现了可以动态变化的ByteBuf初始分配机制。以及如何控制连接之间的消费平衡。