TOC
简述
Filebeat作为Elastic Beats的其中一个组件,用于实现日志文件的ETL操作。他的前身是logstash(ELK里面的L),相对来说更轻量,设计为Beats的其中一个模块而不是独立的项目反映了Elastic对其的定位。
功能上Filebeat作为一个日志ETL工具,可以设想它应该具备以下几个模块:
-
目标采集文件维护:扩大一点可以理解为对整个ETL的整体控制,包括根据配置文件去发现哪些日志需要采集,拉起/回收采集服务等。在Filebeat中这个模块主要是Input(曾经叫做prospectors)
虽然通常的日志采集都是以文件为目标的,但Filebeat还提供了许多不同的input类型。除了基于文件的filestream/log类型之外,还有TCP/UDP/Docker/Redis等,具体可以看官方文档
本文仅讨论文件类型的filestream/log
-
(E,Extract)采集进度管理:具体负责一个单一文件的采集流程,包括记录该文件的标识(文件名/inode/device)、进度(offset)、采集状态(时间/ttl)等。在Filebeat中这个模块主要是Harvester
-
(L,Load)消息输出:目前输出支持多种类型,由于Filebeat的东家Elastic的ES是基于JSON结构的,因此默认输出格式为JSON,但也提供可以自定义输出格式的codec。
基础配置
# start with specified(-c) config and log to stderr(-e) for debug purpose.
./filebeat -c /path/to/root/config/filebeat.yml -e
配置结构
下面是一个比较常见的配置结构,一份通用配置文件,外加若干份子配置文件,每个文件对应一个服务的日志采集配置。
---
# ROOT CONFIGURATION
# ============================== Filebeat inputs ===============================
filebeat.config.inputs:
enabled: true
# Inject sub-configuration files.
path: /path/to/configs/*.yml
reload.enabled: true
reload.period: 10s
# ================================== Outputs ===================================
# Configure what output to use when sending the data collected by the beat.
output:
console:
# Format custom output content in a non-JSON format.
codec.format:
string: 'ts:%{[@timestamp]}, path:%{[log.file.path]}, offset:%{[log.offset]}'
# ================================== Logging ===================================
# Sets log level. The default log level is info.
# Available log levels are: error, warning, info, debug
logging.level: info
---
# SUB CONFIG /path/to/configs/service-01-fs.yml
- type: filestream
enabled: true
recursive_glob.enabled: true
id: service-01-fs
fields:
service: service-01
ipAddr: 172.0.0.1
paths:
- /path/to/log/*.log
- /path/to/log/*.txt
input type: filestream vs. log
从7.14版本开始提供filestream类型的采集组件。相交于旧的log组件,主要有以下优势:
- 性能更好:主要是修改了registry文件的结构:支持增量写registry文件;支持元素合并防止无限膨胀
- 边界问题处理得更好:支持基于output状态维护采集任务的
close.on_state_change.*;- 提供更多功能:支持多种
file_identity用于区分采集文件(而不仅依赖inode+deviceId);更详细的监控metric- 未来社区仅支持filebeat,而log不再维护
自定义字段 & codec.format
在fields配置中添加自定义的字段,如在k8s环境中可以添加容器的TAG信息。默认情况下自定义的字段会整合在fields字段以Object的方式输出给output。如示例配置中添加的fields.service属性,可以在codec中则以%{[fields.service]}的方式提取。更可直接将环境变量注入到fields当中。
多行支持
默认情况下Filebeat的日志输出是以行为单位的,但是有的时候同一条日志可能会跨多行,常见于Java日志打印堆栈;或者print多行文本。这需要配置多行采集以合并分散在多行的同一条日志。如下面这段配置示例了将所有空白字符开头的行往前合并为一条日志:
multiline.pattern: "^\\s"
multiline.negate: false
multiline.match: "after"
multiline.max_lines: 500
offset进度管理 & inode
官方文档介绍了offset来记录每个文件的采集进度——实际上offset是当前进度的字节偏移量。offset在内存中保存了一份最新值,每读取一行日志便逐步递增,同时也会定时持久化到registry文件中。
但是光有offset是无法定位唯一的文件位置的,传统的做法是基于inode+deviceId+offset的方式来标记唯一的文件。由inode+deviceId定义的一个日志文件发生滚动、重命名、移动,都能够找到它的offset,从而实现进度追踪。
不过inode在某些情况下也不可靠,因为操作系统可能会把同一个inode值分配给两个不同的文件。因此在filestream中引入file_identify来更灵活地标记唯一的文件。除了基于inode+deviceId的netive模式,还支持以下几种模式:
-
path模式,可以纯粹基于文件目录来标识文件;滚动日志在重命名之后会被视为全新的文件再次采集(如果新文件在paths目录下)。
-
filgerprint模式,可以基于文件(部分)内容的hash值来标识文件;由于大多数日志都包含递增的时间字段,因此新的日志文件总有不重复的hash值,使得这种方式来标识唯一文件相当可靠。
原理深入
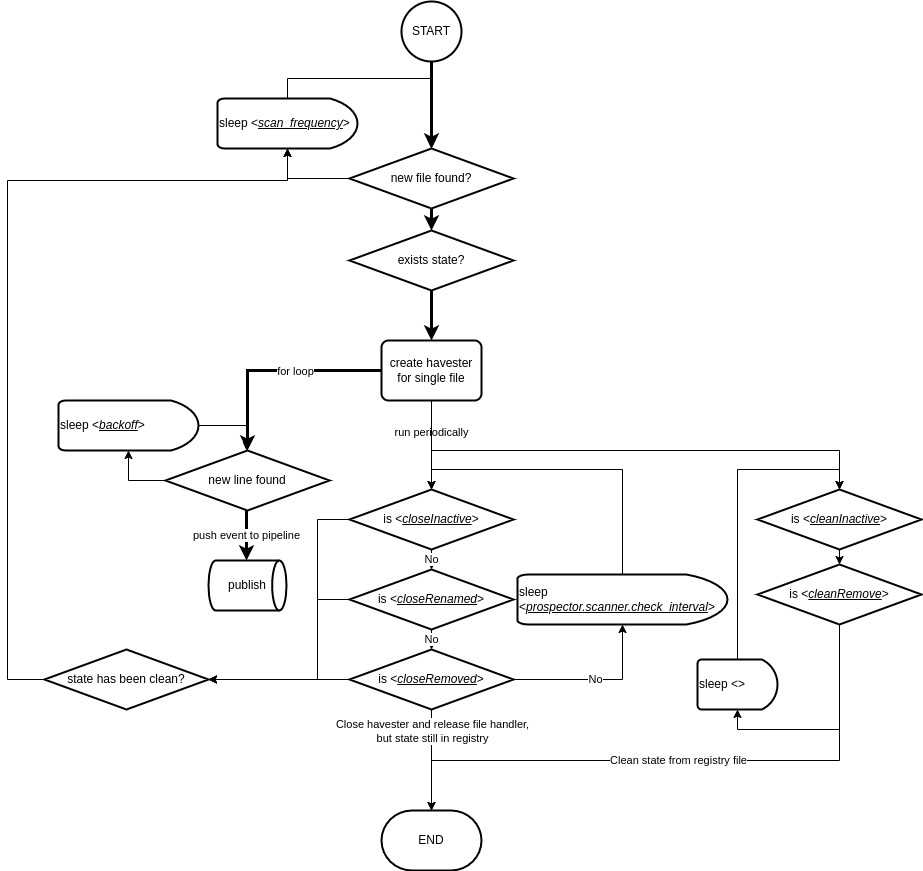
采集一个文件的完整流程是怎样的?
step1.扫描paths为每个文件创建havester实例
在filebeat启动之后,会为每个input拉起一个FSWatcher后台任务每隔check_interval(input:logstream对应配置是check_interval,input:log对应的配置则是scan_frequency)查看input.paths路径上是否有新的文件变动事件(事件类型包括文件的增(新建)删(删除)改(文本追加/删除)),并通知harvester进入对应的工作步骤。
step2.havester根据state启动文件读取流程
FSWatcher对文件的识别依赖于inode+deviceid标识,一个state记录中不存在的标识出现,并判断该文件的修改时间满足ignore_older条件,FSWatcher便当作是新的文件通知harvester进行采集。反之若标识存在,则从state读取其进度接续消费进度。
对于一个全新的日志,由于linux文件系统并不会保存每一行文件的编辑时间,因此harvester会直接从第一行开始采集整个文件。这种策略在大文件采集时,如果状态控制不当(如过短的clean_inactive导致进度删除)会导致大量日志重复。
step3.havester循环读取文件的新内容封装为Event发送下游
在FSWathcer完成对新文件的定位之后,harvester便不断地(当然也有一个退避限速策略backoff)对同一个文件进行内容读取,并封装为Event投递给下游。
除此之外,havester还会启动两个定时任务,间隔为check_interval地检查该文件是否:1.太久未写入(inactive)、2.更名(rename)、3.删除(remove),若是则关闭对应harvester;并判断是否达到了清除(clean)采集状态。区别在于close之后如果文件再次发生变动,可以接续进度,而clean会删除进度,当作全新的文件,从头采集。
inode是什么?
这里介绍一篇文章帮助理解。
是否需要lineId?
根据前面的叙述,file_identify定义了唯一的文件,offset则定义了日志行在该文件中的位置。但是在实践中我们通常还需要line_id,来定义日志行在连续的滚动日志文件中的位置。否则仅依靠offset(哪怕加上不太准确的timestamp),是无法在滚动的时候对日志进行准确排序的。举个例子,在文件滚动的时候,offset会归零,此时便无法按照offset来做排序。使用timestamp,也存在同一时间内多行日志的情况导致排序错乱。哪怕使用timestamp+offset的联合排序,也无法保证在文件滚动+时间戳相同的极端情况下严格有序。
很可惜相关issue表明官方明确拒绝引入lineId,原因总结是:1)lineId在多行日志的场景下难以界定(应该以first还是last作为行号?)2)时间戳足够细应该大致够用(单文件在ms乃至us内打印多行日志的情况比较少见)
但起始业务上需要的实际上不是真实的物理行号,而是一个逻辑上顺序递增的行标识。因此我们还是执着地引入了行号的概念,通过在state中增加一个lineId字段用于持久化,在event生成的时候递增并透传给下游。