TOC
现代数据中心拥有大量的数据来源,这里的说的「大量」,既指来源种类的多,也指数据量的多。如何将这些数据及时(甚至是实时)地导入到数据中心,是所有数据业务的前提条件。Flume是Cloudera开源的一款处理大数据搬迁的工具。这次我们来聊一聊如何用它可靠地处理典型业务以及实现原理。
Flume架构
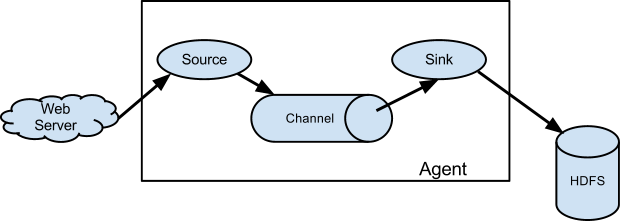
单个Flume进程(统称为Agent)包含3个模块: Source,Channel和Sink。分别处理:
- Source 收集数据,生成模块间流转的数据单位
Event - Channel 在Source和Sink之间传递Event,必要的时候对Event进行持久化,是Flume数据可靠性的一个核心模块。
- Sink 发送数据,将Event导出到下一个Agent,或者其余持久化的模块。(如HDFS,Kafka…)
Flume基础结构图:
在Flume基础机构之上,可以根据业务需要拼接多个Agent形成集群。有趣的是,Flume的Agent可以在集群中无差别地充当任意角色,所有的Agent在进程级别上都是一致的。Agent集群通过avro rpc通信,可以形成简单的点对点串联。

也可以将n个agent集合到一个agent上,由汇总agent对数据做合并处理后批量写入持久化存储。
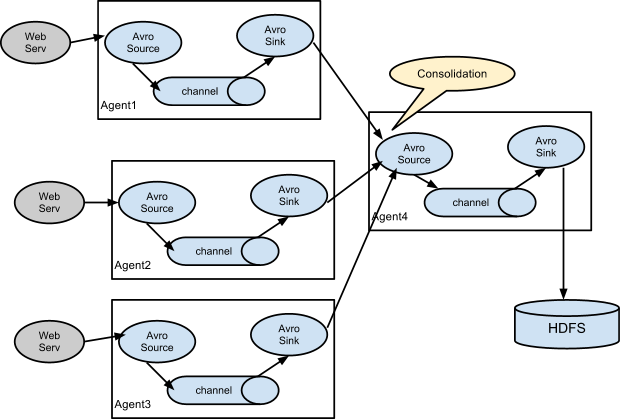
汇总写入可以批量/压缩/减少连接数,比每个agent单独写入效率高。且通过汇总agent来做一些统一的过滤/标记工作(通过interceptor)也比单独agent处理更容易维护。
另外flume也支持冗余channel(通过ChannelSelector)实现将一份数据保存到不同的sink。
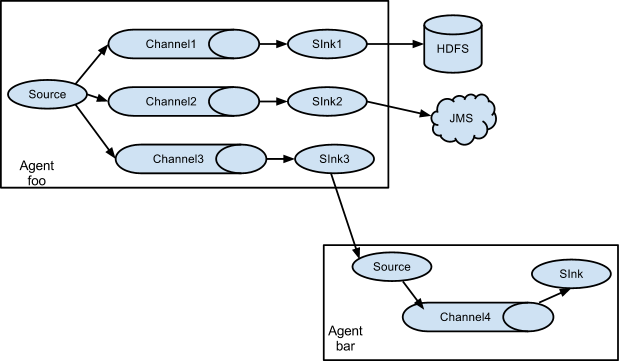
单个source冗余保存到多个sink,常见于将一份数据同时保存在kafka和hdfs,分别做实时和离线处理
实时&高并发&可靠
实时追求的是将客户端产生的数据尽可能快地搬迁到目标保存,粗略地可以通过所有数据到达目标的延迟的方差来衡量。
高并发追求的是单位时间吞吐量,往往通过平均延迟来衡量。实践中往往通过增加机器来水平拓展提高并发性能。
可靠性指的是周期内系统平稳无故障运行的总时间,同时也应该包括问题发生时,对系统影响尽可能小,并能及时恢复。
Flume在各组件的设计中提供了各种机制,了解各种机制的原理并知晓其优缺点,是我们实现上述目标的基础。
Source
Source用于是Flume的数据源头,常用的实现有:
ExecSource,执行Unix进程,将输出的每一行封装为一个Event。SpoolDirectorySource,监控指定目录(称为spooling directory)下的新文件,新文件的每一行作为一个Event。注意文件一旦新增不能修改。AvroSource,基于avro+Netty实现的Source。通常与AvroSink配合使用,形成Flume多Agent之间数据流转。
ExecSource
ExecSource内部通过一个Executors.newSingleThreadExecutor()线程池来执行Unix进程,产生的Event先缓存在一个内部的ArrayList中,等到数据堆积或者时间累积达到条件,触发一次flush批量写入Event到Channel(s)。
一次批量插入中,任意Event->channel失败均会导致整体抛出异常,并导致整个Source中断退出。
ExecSource无状态,缓存数据保存在内存中,崩溃会导致数据丢失。另外业务上常用tail -F来监听文件,Source崩溃重启过程可能导致重复消费(文件生成速度低于tail的起始行数)/丢失(跟重复相反) 或者 运气好的时候无影响(文件生成新行数跟起始行刚好持平)。这都需要我们结合不同的情况针对性地处理。
ExecSource的一些问题
通过kill -9 杀死Source进程时,会导致Unix子进程未关闭,可以通过添加钩子方法显式关闭来解决
SpoolDirectorySource
SpoolDirectorySource支持监控一个目录下的文件,按行解析成Event。底层实现是通过一个ScheduledExecutorService.scheduleWithFixedDelay()方法定时(500ms一次)扫描目录,按文件修改时间从旧到新的顺序读。
通过tracker机制将读取进度(文件偏移量)持久化到本地文件,Event成功提交channel之后commit更新trackerFile。重启Source之后可以根据trackerFile继续读取进度。tracker机制可以保证at-least-once,但是可能重复消费。
AvroSource
AvroSource本质上是一个基于avro-Netty实现的RPC服务端,它能接受AvroSink的数据(形成Agent之间的连接),也可以接受任何实现了avro协议数据源发送的数据。此Source的核心逻辑落在org.apache.avro.ipc.NettyServer,这是avro自己实现的一个Netty服务器,内部负责将接收到的netty数据包解析为AvroFlumeEvent对象回调append方法,在append中把转换成Flume的Event实例并发送给Channel。
回调方法append之后,NettyServer会给客户端一个成功响应,以此来保证数据落地到Channel。
Channel
Channel是Source生成Event之后的缓存组件,类似于Flume内部的消息队列,它存在的意义为:
- 削峰填谷,为读端和写端兼容短时间的不一致读写速率
- 消息分发,结合ChannelSelector可以将一个Source生成的Event分发到多个Channel
- 事务性,Channel支持简单的事务功能,能够实现
at-least-once语义
Flume默认提供了两个Channel的实现
MemoryChannel
是基于内存的Channel,Event缓存在内存队列中等待Sink消费。这样做的好处和坏处都非常明显,好处是可以非常快速地吞吐Event,坏处则是一旦系统崩溃,所有的信息都将丢失。同时因为内存容量较小,可以支持缓存Event的数量也比较少,当消费端出现问题导致消息阻塞时,Source也可能因此卡住(甚至丢失数据)。对于追求可靠性的应用,MemoryChannel并不是实际的选项。
MemoryChannel中包括两个容量核心的容量概念,一个是Event容量capacity,还有一个事务内Event的容量transactionCapacity。在计算可用容量时,flume使用了非常机智的一个方式,使用
Semaphore信号量来模拟内存使用量。具体做法是初始信号量设为跟容量相等,消耗内存时则在信号量上require,即实现了内存使用量的控制,也解决了线程等待的问题。值得学习
FileChannel
是基于磁盘的Channel,所有的Event操作都会封装成事件持久化到log文件中。这样当系统崩溃,我们还是可以通过log文件恢复现场。 具体实现上,FileChannel设计了三个核心的概念来处理持久化Event:
FlumeEventQueue
在内存中维护一个FlumeEventQueue队列,和MemoryChannel不同,它保存的不是Event的实际内容,仅保存Event在持久化文件中的指针。这样内存中维护Event的空间成本大大降低。
log文件
在磁盘中维护一系列的log文件,Sink或者Source对Channel的任意请求都会先落地为一个执行日志。这些请求通过protobuf格式封装,表示为4种类型的Event:
Put (事务ID,日志序号,event实体)记下一个PutEvent表示完成了一次新增Event操作,这个操作归属于指定Id的事务Take(事务ID,日志序号,Event实体所在文件序号,Event 偏移量)记下一个TakeEvent表示Sink从Channel消费了一个Event,该Event所属的事务ID/从哪个log文件拉取的/在这个log文件中他的offset是多少Commit(事务ID,日志序号,commit类型)记下一个CommitEvent表示Source或者Sink提交了一个事务,这个事务的的类型也被记录下来(仅可选put/take,也就是说在一个事务中,只能做put或者take操作。MemoryChannel可以在同一个事务中做put/take)。Rollback(事务ID,日志序号)记下一个RollbackEvent表示回滚了一个事务,如果当前事务做了put操作,所有的Event会被丢弃,如果当前事务做的是take操作,那么所有Event将回滚为未消费状态。
注意到所有Event中都包含一个日志序号,这是全局维护的一个递增序列,事实上在FlumeEventQueue的底层保存的是一个有序的map,其中的key就是这里的日志序号,这样做的好处是将内存偏移量变成更容易编程理解的序号。
checkpoint
有了log,在保证Event完整且有序地写入log文件之后,完全可以通过完整地重跑所有Event来恢复任意时刻的状态(本质上就是恢复FlumeEventQueue这个队列)。但是这样显然太慢了,所以就有了快照checkpoint。在物理上我们会看到checkpoint包括3个文件:
checkpoint记录每次checkpoint操作时整个队列的明细数据,包括当前最新的日志序号 和 已commit的Event列表,以及checkpoint正常开始及结束标记。inflightputs文件 保存已提交未commit的putEventinflighttakes文件 保存已提交未commit的takeEvent
有这些文件就可以直接恢复checkpoint写入那一刻的channel状态,省去了重跑log,启动速度快很多。但checkpoint的写入是由一个独立的线程定时触发的,面临两个问题:
- checkpoint保存的不是系统崩溃时最新状态,所以使用checkpoint恢复之后,还要使用log文件重跑从checkpoint保存的最新日志序号开始的所有日志。当然这比重跑整个log队列还是快很多
- checkpoint执行的过程中可能系统异常退出,导致checkpoint写入不完整。启动的时候系统发现checkpoint缺少正常的开始和结束标记,就会退化成使用log重跑,效率低。
FileChannel的优缺点几乎和Memory反过来,能否有什么方法可以糅合两者的优点? 我的理解是没有,虽然美团技术团队给出了DualChannel方案,在消息堆积多的时候使用FileChannel,当需要高吞吐时则使用MemoryChannel。但私以为这样MemoryChannel会丢数据的问题依然没有解决,不能做到100%可靠。所以在要求严格不丢数据的场景,使用FileChannel目前看来成了唯一的选择。
但是FileChannel的处理速度低怎么办? 可以通过增加dataDirs并发io来增加速度(当然本质上还是磁盘IO)。也可以通过增加Channel来提高并发。但这个时候需要我们自己实现ChannelSelector来实现Event分发。
默认的ChannelSelector
Flume1.4.0只实现了两种:
- ChannelSelector: MultiplexingChannelSelector(根据mapping+header配置来选择每个Event的去向,可以实现Channel路由功能)
- ReplicatingChannelSelector(所有配置的channel均会接收source的每一个Event)
竟然没有shuffle的实现…
Sink
Sink处理的是将channel中的数据拉取出来,写入到目标数据源。每个Sink只能处理一个Channel的数据。跟Source类似,拉取操作是在事务控制下的,可以保证at-least-once语义的消费。常用的Sink有:
RollingFileSink
提供将Event持久化到文件的功能,同时支持定时刷写新文件(rolling)。
HDFSEventSink
提供将Event持久化到HDFS的功能,同时支持kerberos校验(这个等于是提供了kerberos认证的demo代码)
其他类似的还提供了hbase,kafka,es等等的Sink实现,逻辑上并没有太多的差异,都是写数据,有需要的可以拿过来当个客户端参考代码,这里不做赘述。
Flume部署
在了解了Flume本身的架构之后,我们可以知道如何使用Agent来完成可靠的数据传输,通过FileChannel,重启服务并不会造成数据丢失。那么下一步就要上升到应用层面来讨论实际业务中如何做服务的可靠性和拓展。
首先是Agent进程,简单的可以使用supervisor来管理进程重启。监控方面,1.4.0版本的Flume在这方面做得还比较少,仅仅是将一些事件做了counter计数。如果要对Flume的运行情况,包括流量,event处理时间,channel缓存数量等的监控,还需要引进第三方的工具。
在确保了单一Agent进程的可靠之后,自然而然要考虑的就是如何横向拓展性能。Agent根据不同的类型的Source可以采用不同的横向拓展方案增加机器,对于SpoolDirectorySource由于单个目录同时只能被一个Source消费,所以增加source的前提是增加目录的数量; 而ExecSource横向增加的前提则跟实际执行的unix命令有强关联关系; AvroSource则方便的多,增加Agent数量并不会影响集群,只需要消息生产者将数据负载均衡地写入到新Agent即可。