TOC
锁的设计目的是为了让多线程并发时,控制线程对某一资源的使用。简单的情况就是控制同时只能有一个持有锁的线程访问资源,这是本文要讨论的。
锁的基础
讨论锁, 必然会涉及3种对象:
- 被锁住的”对象”(称为临界区)
- 锁本身
- 要访问被锁”对象”的实例(即竞争线程)
锁的基础是可以绝对可靠的排他, 否则开锁的一瞬间多个竞争线程同时进入临界区, 这就违背了锁的语义。
先看一段代码:
public class BadLock {
private static boolean lock = false;
public void lock(boolean lock) {
while (lock);
lock = true;
}
public void unlock(boolean lock) {
lock = false;
}
}
lock()方法通过while一直循环判断lock是否为true(这个动作称为自旋spin),lock为true表示有其他线程占用资源,需要当前线程等待。
直到占有锁的线程通过unlock()方法释放锁,即将lock置为false,当前线程发现lock==false跳出自旋,获取锁。
看似简单,但是事实却比这复杂。加锁动作可以简化为三个核心步骤:
lock被持有锁的线程置为false- 当前线程发现
lock变为false - 当前线程将
lock变为true(开始进行排他操作)
操作之中,可能有更多的更多的其余线程也在同时改变lock的状态。
-
如果步骤1-2之间
lock被其他线程改为true, 当前线程就无法发现lock的改变, 自旋继续。 这个没有问题。 -
如果步骤2-3之间
lock被其他线程改为true(也是通过lock()方法), 那就会有多个线程同时认为自己获取锁, 进入到临界区。
这里的主要问题就在于步骤2-3的操作不是原子性的,可能被插入其他的操作。好在现代的操作系统中提供了read-modify-write(RMW)原子操作,可以原子地执行读-改-写操作。让2-3变成原子操作, 最简单的锁(SimpleLock)就实现了。这种锁简单,但是不够公平(从先申请先获取的角度来说公平),因为每次lock释放之后,所有等待锁的线程不论先后有同等机会获取锁。
CLH自旋锁
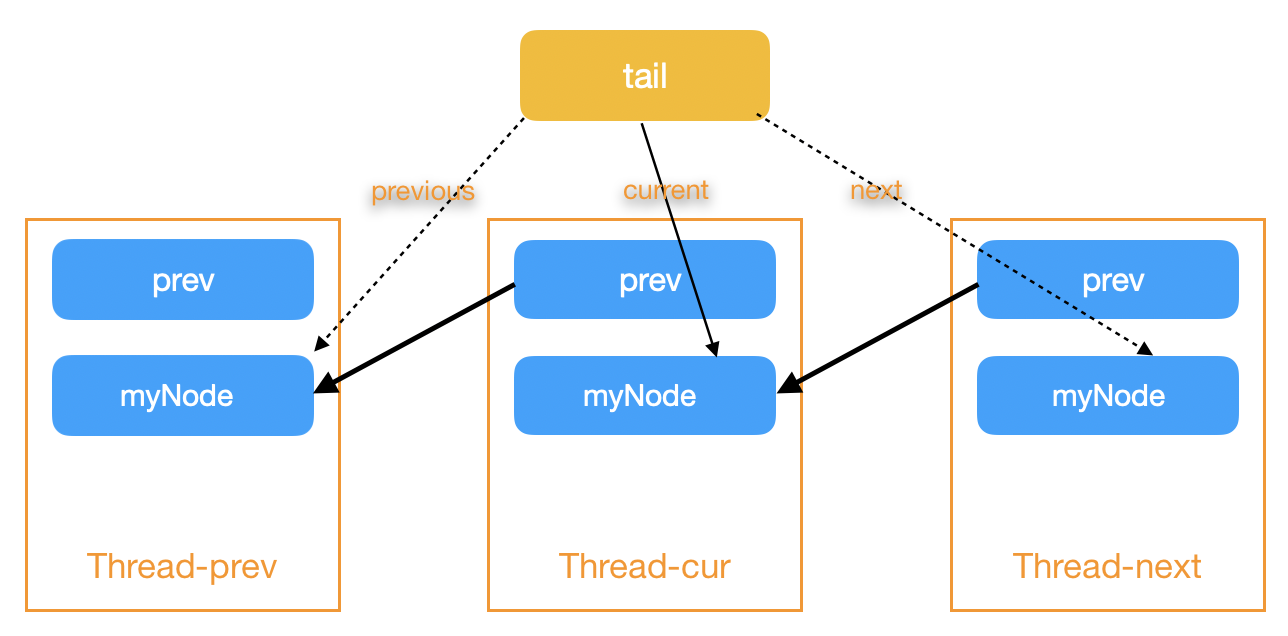
CLH(Craig,Landin and Hagersten。名称来自发明人的名字 )自旋锁是一种基于隐式链表(节点里面没有next指针)的公平的自旋锁。 它的原理是通过一个prev变量将所有等待锁线程排队, 任意一个线程只等待队列中前一个线程释放锁,下图解释了自选锁的工作:
死锁问题
注意这里在设计上将当前节点myNode和前驱节点myPred区分开, 是否想过可以将myPred去掉, 简化成只有myNode? 答案是不行, 因为仅有前驱节点的时候, 如果不加其余优化, 会导致死锁。 比方说现在有T1和T2两个线程, T1是T2的前驱节点且当前拥有锁。 T1释放锁(position T1-1)之后马上又尝试获取锁(position T1-3), 在这个过程中T2将前驱T1写入tail(position T2-1), 之后T1获取前驱节点信息(position T1-2)是其本身, 这时T1并未获取锁, 所以永远在等待自身释放锁(position T1-3)。
造成这种现象的根源在于tail属于共享对象, 对它的切换不是原子性的, 以至于使得前驱节点指向当前节点。 那么我们通过线程变量pred, 解开这种循环依赖, 搞定。
public class CLHLock implements Lock {
private final AtomicReference<QNode> tail;
private final ThreadLocal<QNode> myPred;
private final ThreadLocal<QNode> myNode;
//。。。 省略初始化操作
public void lock() {
QNode qnode = myNode。get();
qnode.locked = true;
QNode pred = tail.getAndSet(qnode);// position T2-1, position T1-2
myPred.set(pred);
while (pred.locked){} // position T2-2, position T1-3
}
public void unlock() {
QNode qnode = myNode。get();
qnode.locked = false;
myNode.set(myPred.get()); // position T1-1
}
private static class QNode { volatile boolean locked;}
}
MCS自旋锁
设计随着环境变化, CLH如果遇上NUMA(Non Uniform Memory Access,非统一内存访问,是一种用于多处理器的电脑内存体设计,内存访问时间取决于处理器的内存位置。 在NUMA下,处理器访问它自己的本地存储器的速度比非本地存储器快一些。)架构的系统, 也出现了新的优化空间。 由于在传统的架构当中, 多个线程共享L1 cache, CLH中while命令自旋检查的对象虽然属于不同的线程, 但是同样落在一个cache中。 而面对NUMA这种架构, 不同线程的变量可能在不同的cache中, 这样就导致了需要加一层cache一致性的消耗。 所以MCS应运而生。
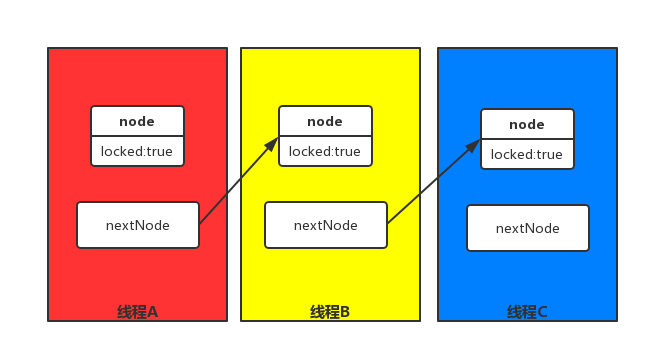
MCS是一种基于显式链表(节点里面拥有next指针)公平的自旋锁。 它的原理是让当前节点保存一个指向后继节点的指针, 并令所有的后继节点均在自己的对象上自旋, 持有锁的节点释放锁的时候主动通知后继节点。
注意, MCS的主要优势在于自旋的对象是线程内对象还是跨线程对象, 因为这两种资源的访问在NUMA架构下可能会导致比较大的性能差异。
AQS 的CLH增强锁
AbstractQueuedSynchronizer(AQS)是Java并发包的基石之一,ReentrantLock, ReentrantReadWriteLock, CountDownLatch, Semaphore等类均继承自此抽象类, 按照AQS的文档说法, 此类提供了一个框架, 用以实现依赖同步队列。 。
AQS的核心在于以下几个部分:
- Node 等待节点。 类似于CLH中的QNode, 用以实现等待线程的双向队列。
- state 的管理, 这部分决定了不同AQS实现类的不同特性。 AQS通过暴露
tryAcquire和tryRelease等几个待实现方法的方式给子类来管理state。 - 基于LockSupport的竞争锁机制。 这部分是AQS的核心。
系列文章下一节我们将会以ReentrantLock, CountDownLatch为例, 深入了解如何借助AQS实现不同类型的锁。